- Review: Applications of Support Vector Machines in Chemistry, Rev. Comput. Chem. 2007, 23, 291-400
Pattern recognition develops and applies algorithms that recognize patterns in data. These techniques have important applications in character recognition, speech analysis, image analysis, clinical diagnostics, person identification, machine diagnostics, and industrial process supervision. Many chemistry problems can be solved with pattern recognition techniques, such as: recognizing the provenance of agricultural products (olive oil, wine, potatoes, honey, etc.) based on composition or spectra; structural elucidation from spectra; identifying mutagens or carcinogens from molecular structure; classification of aqueous pollutants based on their mechanism of action; discriminating chemical compounds based on their odor; classification of chemicals in inhibitors and non-inhibitors for a certain drug target.
We now introduce some basic notions of pattern recognition. A pattern (object) is any item (chemical compound, material, spectrum, physical object, chemical reaction, industrial process) whose important characteristics form a set of descriptors. A descriptor is a variable (usually numerical) that characterizes an object. A descriptor can be any experimentally measured or theoretically computed quantity that describes the structure of a pattern: spectra and composition for chemicals, agricultural products, materials, biological samples; graph descriptors and topological indices; indices derived from the molecular geometry and quantum calculations; industrial process parameters; chemical reaction variables; microarray gene expression data; mass spectrometry data for proteomics.
The major hypothesis is that the descriptors capture some important characteristics of the pattern, and then a mathematical function (machine learning algorithm) can generate a mapping (relationship) between the descriptor space and the property. Another hypothesis is that similar objects (objects that are close in the descriptor space) have similar properties. A wide range of pattern recognition algorithms are currently used to solve chemical problems: linear discriminant analysis, principal component analysis, partial least squares (PLS), artificial neural networks, multiple linear regression (MLR), principal component regression, k-nearest neighbors (k-NN), evolutionary algorithms embedded into machine learning procedures, support vector machines.
An n-dimensional pattern (object) x has n coordinates, x=(x1, x2, …, xn), where each xi is a real number, xi∈R for i = 1, 2, …, n. Each pattern xj belongs to a class yj∈{-1, +1}. Consider a training set T of m patterns together with their classes, T={(x1, y1), (x2, y2), …, (xm, ym)}. Consider a dot product space S, in which the patterns x are embedded, x1, x2, …, xm∈S. Any hyperplane in the space S can be written as
The dot product w•x is defined by:
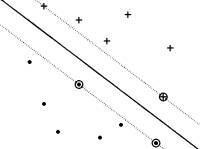
A training set of patterns is linearly separable if there exists at least one linear classifier defined by the pair (w, b) which correctly classifies all training patterns (Figure 1). This linear classifier is represented by the hyperplane H (w•x+b=0) and defines a region for class +1 patterns (w•x+b>0) and another region for class -1 patterns (w•x+b<0).
 |
| Figure 1. Linear classifier defined by the hyperplane H (w•x+b=0). |
After training, the classifier is ready to predict the class membership for new patterns, different from those used in training. The class of a pattern xk is determined with the equation:
Therefore, the classification of new patterns depends only on the sign of the expression w•x+b.
|